4 min to read
Replacing Reality on the Vision Pro

Introduction
It’s been a while since I posted so I thought I’d do one on a subject not many know about.
In undergrad, I wrote a research thesis on diminished reality, an interesting subfield of mixed reality, and I would like to demonstrate some of the fun I’ve been having building a DR pipeline on the AVP for this project. The thesis is here, if you would like to read it in full: Graduation Thesis.
What is DR?
Diminished Reality (DR) is a subset of Mixed Reality focused on the removal, replacement, or minimization of the user’s environment through the integration of Vision and Spatial Computing. The current technical pipeline uses precise real-time object segmentation and image inpainting to replace occluded regions with geometrically consistent background textures. To maintain “visual invisibility,” the system must resolve the diminishment-observation loop by ensuring synthesized content adheres to 6DOF pose tracking and local epipolar constraints.
Current research focuses on overcoming latency bottlenecks in dense semantic scene reconstruction and ensuring temporal coherence under dynamic illumination using generative synthesis models.
The seminal work into this genre, where the authors explore more simplistic techniques, is Towards Understanding Diminished Reality by Cheng et al.
The principal pipeline can be broken down into two major steps: Observation – Diminishing. Once we master both steps, the pipeline becomes robust and seamless.
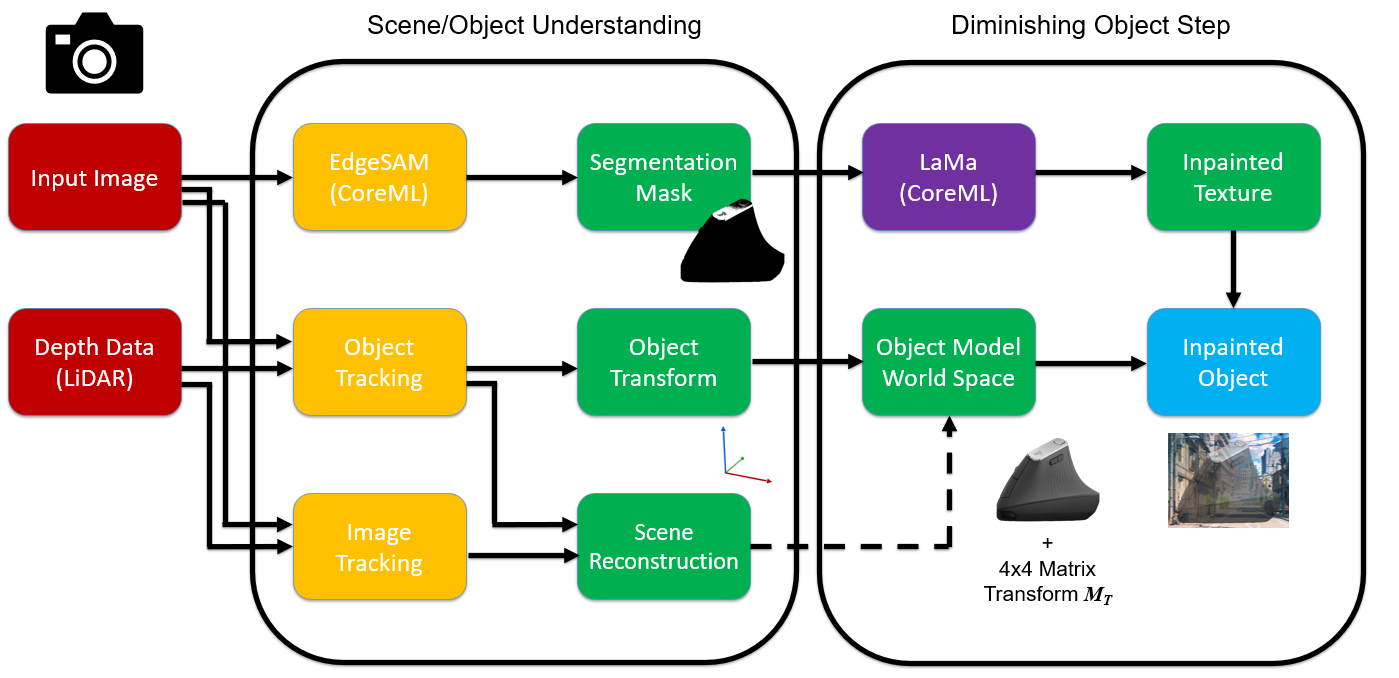
Identifying and Observing the Object
The observation stage takes the form of a multi-modal image acquisition pipeline from the headset, using either the Photo-Video camera on the HoloLens 2 or the Video-See-Through (VST) pipeline of the Apple Vision Pro. I found that it was incredibly hard to diminish anything on the hololens due to its Optical-See-Through lens that could not fully overwrite image data.
For removal of the target, I used a point-prompt-based segmentation strategy using lightweight models like EdgeSAM or FastSAM to generate precise binary masks (Although, with the rate new SAM models are being developed, I would love to try this on newer SAM versions).
On the Vision Pro, this perception is further enhanced by a built in 3D photogrammetry-based tracking system which utilizes .usdz models to ensure robust object recognition across varying viewpoints.
I also tried optimizing the segmentation and tracking modules via Core ML and Metal shaders to minimize latency by processing data directly on the device’s Neural Engine.
The final output of this stage is a dual-input packet containing the raw RGB frame and the isolated Region of Interest (ROI) mask, which provides the necessary spatial context for the subsequent synthesis.

Diminishing the Object
To inpaint the object, I pass the masked ROI into a deep inpainting engine, specifically LaMa.
This engine reconstructs the occluded pixels by synthesizing a background that maintains structural and textural continuity – although it could be improved for fast-feedback systems, such as mine.
To ensure the result is geographically consistent with the physical room, the system maps the inpainted texture onto a localized 3D mesh rather than a simple 2D plane. Techniques such as triplanar mapping are utilized during this rendering phase to prevent texture stretching on irregular surfaces and maintain visual fidelity.
Finally, the processed content is composited back into the user’s view using the headset’s rendering pipeline, effectively “diminishing” the physical object in real-time. See some examples below for yourself!

Samples
Here are some more examples from my work. I kind of just used any objects that were easily modeled by photogrammetry and available as well. The practical use case here is to diminish your phone – a package of everlasting entertainment and boredom-killers at your fingertips.
I was interested in how we could mitigate phone addiction, distraction, and improve attention in mixed reality and this study was one of the examples of doing so:

 In the background you can see the beautiful Duke scenery and how the LaMa model tries to compensate and guess those spaces with deep learning.
In the background you can see the beautiful Duke scenery and how the LaMa model tries to compensate and guess those spaces with deep learning.
As a side note, I also evaluated the immersiveness of my diminished scenes with VLMs. This work is similar to the work I did for this article on using VLMs in mixed reality spaces.
Limitations and Future
- My system has strong reliance on pre-scanned 3D models, which points to future research into real-time object learning and spontaneous photogrammetry to improve usability in uncontrolled environments. Perhaps we could approach a reality where headsets can work in conjunction with handheld devices to easily scan entire rooms and objects from multiple viewpoints simultaneously.
- Technical performance is constrained by hardware, which could be mitigated through deeper Metal Compute Pipeline integration, including adaptive tiling and model pruning to support more advanced diffusion-based inpainting. I’m sure the ML people are already working on these optimizations, though.
- The current reliance on a screen-sharing workaround for raw image access introduces significant latency as well (courtesy of modern tech giants making these Camera frames inaccessible to developers), requiring the development of optimized wireless communication or shared memory protocols to achieve better performance.

